В этом разделе рассматривается механизм ранжирования паттернов, который применяется в стандартном режиме работы Code.
При обработке каждого запроса клиента Code сопоставляет реплики пользователя со всеми активными правилами (паттернами). Далее выполняется ранжирование полученных гипотез по алгоритму, рассмотренному ниже.
После выполнения ранжирования, гипотеза с наибольшим весом отправляется на обработку в сценарий, то есть запускается выполнение сценария в выбранном стейте. Остальные гипотезы разбора сохраняются в массиве $context.nBest, если в chatbot.yaml задан соответствующий параметр.
Вычисление конечного веса каждого паттерна состоит из следующи�х этапов:
- Вычисление
cost; - Вычисление
score; - Добавление весов из правил
$weight; - Контекстное ранжирование.
Вычисление cost
cost — штраф, который начисляется сопоставлению, если фраза пользователя не полностью соответствует паттерну. Рассчитывается как сумма штрафов по всем парам слово — паттерн. Расчет штрафа для каждой пары зависит от правила.
Формула расчета:
cost = sum c(r,w,p)
Где:
c- штрафcost;r- правило;w- слово;p- текст паттернаlen(w)- длина слова (фомула в таблице);ed(w,p)- расстояние редактирования между словом пользователя и словом из паттерна (формула в таблице).
Где r принимает значения:
| r | Формула | Соответствие паттерну |
|---|---|---|
word | 0 | слово |
spelling | ed(w,p)*0,5 | * |
lemma | 0 | ~lemma |
morph | 0 | $morph<часть речи и/или граммема> |
stem | ed(w,p)*0,97 | корень |
regex | 0 | $regexp<литералы и метасимволы> |
star | len(w)*1+0,01 | * |
garbage | len(w)*0,99 | $nonEmptyGarbage |
oneWord | len(w)*0,98 | $oneWord |
punctuation | len(w)*0,1 | * |
namedEntity | 0 | $entity<именованная сущность> |
Вычисление score
score — нормализованный обратный штраф. Предполагалось, что score будет принимать значения в диапазоне от 0 до 1, но с вводом дополнительного штрафа для паттерна * диапазон значений расширился и включает в себя отрицательные значения.
Формула расчета:
S = 1 - c/(сумма len(w)+ сумма len(p)*0.1)
Здесь:
len(w)- длина слова;len(p)- длина символов пунктуации;c- штрафcost.
Добавление весов $weight
На этом этапе добавляются значения из правил $weight, если они использовались в паттерне.
Синтаксис: $weight<a+b>
Вес, задаваемый в паттерне $weight, добавляется весу паттерна по формуле:
S = S*a + b
Где:
w— вес паттерна;aиb— значения, заданные в$weight.
a и b — произвольные вещественные числа, которые отличаются от параметров a и b следующим:
b— сдвигает значение веса на постоянное значение, то есть увеличивает наb.a— мультипликатор, изменяет значение веса линейно, то есть увеличивает вaраз.
Подробнее о принудительном изменении весов паттернов читайте в разделе Изменение веса паттерна
Контекстное ранжирование RankByContext
RankByContext — ранжирование гипотез разбора в соответствии с контекстным расстоянием.
Вычисление контекстного расстояния
Так как контекстное ранжирование непосредственно связано с контекстным расстоянием, рассмотрим процесс его определения.
Контекстное расстояние — расстояние между узлами в дереве тем. Определяется параметрами:
session.contextPath— текущий контекст беседы;fromState— параметр обрабатываемого паттерна.
cd = depth(contextPath) - depth(fromState)
Гд�е:
depth— глубина пути.cd—context distance, контекстное расстояние.
Значения contextPath и fromState всегда удовлетворяют условиям:
- Строка
contextPathначинается со строкиfromState. - Контекст беседеы
contextPathдлиннее или равен параметраfromState.
Эти условия являются обязательными для активации любого правила.
Рассмотрим вычисление контекстного расстояния для простого смартапа, сценарий которого имеет вид:
Укажем fromState для сценария:
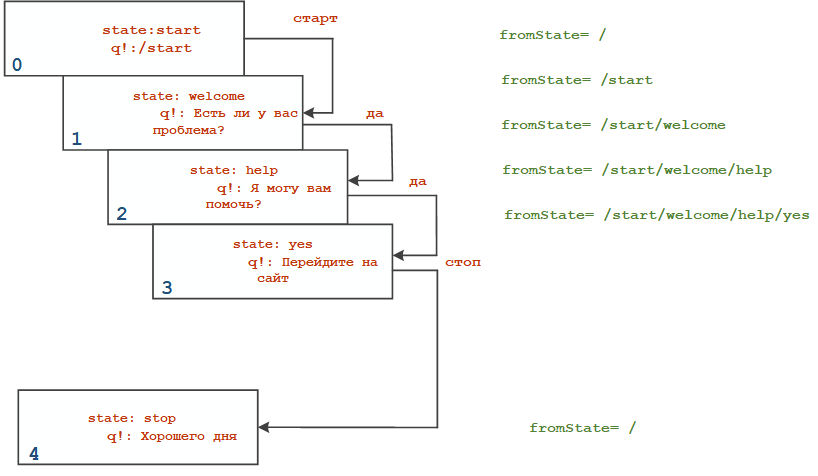
Несколько вариантов общения клиента с ассистентом:
-
Клиент и�нициирует общение с ассистентом:
/start. В этом случаеcontextPath=/иfromState=/. Формула вычисления контекстного расстояния принимает вид:cd = ('/' - '/')=0 -
Клиент инициирует диалог и говорит ассистенту
да. В этом случаеcontextPath=/startиfromState=/start. Формула вычисления контекстного расстояния принимает вид:cd = ('/start' - '/start')=0 -
Клиент останавливает ассистента после
state:yes. В этом случаеcontextPath=/start/welcome/help/yesиfromState=/. Формула вычисления контекстного расстояния принимает вид:cd = ('/start/welcome/help/yes' - '/start')=0
Вычисление конечного веса паттерна
Конечный вес паттерна вычисляется по формуле:
S_c = S*a - b
Здесь:
S_c— конечный вес паттерна, после этапа контекстного ранжирования.aиb— коэффициенты контекстного штрафа.
Коэффициент a вычисляется как (формула в формате KaTeX):
a = 1 - p_1 \displaystyle\sum_{i=1}^{cd} \dfrac{1}{i}
Коэффициент b вычисляется как:
b = cd*p_2
Где:
p_1— коэффициент мультипликатора.p_2— коэффициент сдвига.
Параметры p_1 и p_2 можно задать в конфигурационном файле chatbot.yaml. Значения параметров по умолчанию:
p_1 = 0.2;p_2 = 0.01.
Рассмотрим подробнее параметры a и b.
Параметр a — прогрессивный мультипликатор, который уменьшает вес паттернов, находящихся в дереве тем далеко от текущего контекста беседы.
При этом параметр рассчитывается так, что разница между паттернами, находящимися на cd=0 и cd=1, будет более значительной, чем между cd=5 и cd=6.
Таблица значений параметра a для различных cd со значением p_1 = 0.2:
| cd | Формула | a |
|---|---|---|
| 0 | 1-0 | 1 |
| 1 | 1-0.2 | 0.8 |
| 2 | 1 - 0.2 - 0.2/2 | 0.7 |
| 3 | 1 - 0.2 - 0.2/2 - 0.2/3 | 0.6333 |
Параметр b - постоянный сдвиг. Обеспечивает правило: при появлении двух одинаковых правил с нулевым весом, например, $oneWord, заданных на различных контекстах, всегда будет выбрано то правило, которое ближе всего к contextPath.
В данном случае параметра a недостаточно, так как при S=0 параметр a не изменит результирующее значение Sc.
Формулы расчета Sc при различных cd:
| cd | Формула |
|---|---|
| 0 | S |
| 1 | S*0.8 -0.01 |
| 2 | S*0.7 -0.02 |
| 3 | S*0.6333 -0.03 |